与传统神经网络模型的训练类似,大语言模型的通常也会使用批次梯度下降进行模型参数的训练,同时为保证训练的稳定性和效果,还会针对学习率、优化器参数等超参数进行调整。本文就针对这些策略做一篇小结。
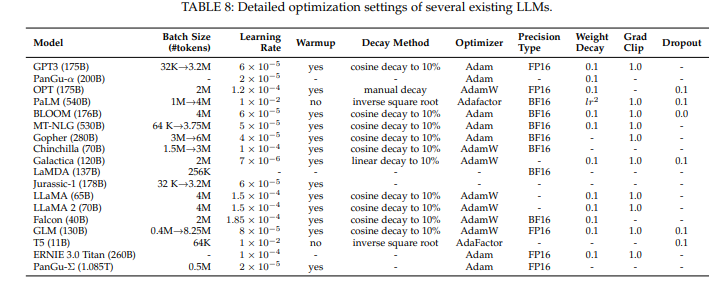
图9-1. LLM超参优化方案
图9-1展示的是即有大语言模型在训练的时候涉及的超参数调整策略,其中超参数包括批次大小学习率、优化器、精度类型、权重衰减、梯度裁剪以及丢弃率。
batch_size(批次大小)
表示单次训练迭代使用的样本数量,也间接表明了处理的token量。在数据集加载部分,我们曾提到,现在很多工作都采用了动态批次调整策略,即在训练过程中逐渐增加批次大小,最终达到百万级别。例如,GPT-3 的批次大小从 32K 个词元逐渐增加到 3.2M个词元,这是因为较小的批次反向传播的频率更高,训练早期可以使用少量的数据让模型损失尽快下降;而较大的批次可以在后期让模型的损失下降地更加稳定,使模型更好地收敛。
使用Hugging Face Accelerator动态调整批次方案, 代码段9-1。
"""
从初始值(如128)开始尝试,若触发OOM则自动减半(64→32→16…),
直到找到可运行的批次大小
"""
>>> from accelerate.utils import find_executable_batch_size
>>> @find_executable_batch_size(starting_batch_size=128)
... def train(batch_size, model, optimizer):
... ...
>>> train(model, optimizer)
动态批次调整过程,通常会涉及到梯度累积。梯度累积(Gradient Accumulation)是一种通过多次小批量计算梯度并累积后统一更新参数的训练优化技术。其核心在于模拟大批量训练效果的同时突破显存限制。
对于批次大小有以下结论:
全局批次大小 = batch_size × gradient_accumulation_steps,其中batch_size 即为当前设定的批次大小,gradient_accumulation_steps 即为梯度累积步数。
若 batch_size=8,gradient_accumulation_steps=4,则: 全局批次大小 = 8 × 4 = 32,这等效于一次性用 batch_size=32 的样本进行训练,但显存仅为batch_size=8 的开销。基于DeepSpeed 配置的批次调整,代码段9-2。
"train_batch_size": "auto", #全局批次大小
"train_micro_batch_size_per_gpu": 8, #每块GPU处理的批次大小
"gradient_accumulation_steps": 4, #累计梯度步数需要注意的是,在使用梯度累积的时候,需要同步调整学习率参数。
Learning Rate(学习率)
学习率(Learning Rate)是机器学习和深度学习中最关键的超参数之一,它控制模型参数更新的步长大小。在梯度下降算法中,参数更新公式为式-1:\(\)
$$ θ_{new}=θ{old}−η⋅∇J(θ_{old})$$
其中 \(η\)代表学习率,\(∇J(θ)\)是损失函数对参数的梯度。学习率本质上是梯度向量的缩放标量,决定了模型在优化过程中“探索方向”的响应强度。
学习率的调整,包括学习率预热和衰减两个阶段。
学习率预热,指在训练初期逐步从小学习率过渡到预设初始学习率的过程。其核心目标是通过温和的起步,帮助模型在参数随机初始化的阶段稳定收敛。
常用的学习率预热策略包括:
- 线性预热(Linear Warmup):
在前N步内,学习率从0线性增长至预设值\(η\)。
- 指数预热(Exponential Warmup):
学习率按指数曲线增长,式-2
$$η_t=η_0×(1+γ)^t$$
实现更平滑过渡,适合需要渐进适应的复杂模型,比如CNNs和RNNs。
- 余弦预热(Cosine Warmup):
结合余弦退火思想,预热阶段学习率按余弦函数增长,随后进入衰减阶段(注意,余弦预热包含增长和衰减来个阶段)。适合需要周期性调整的大规模预训练任务,比如基于transformer 架构的大模型。
典型的预热阶段学习率调度器配置,代码段9-3。
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 1000
}
}armup_min_lr:
预热阶段起始学习率,表示训练第 0 步的学习率为 0。 通过从零开始逐步增加学习率,避免模型在初始阶段因随机参数直接接受大幅梯度更新导致的震荡。
warmup_max_lr:
预热阶段目标学习率,即经过 warmup_num_steps 步后达到的峰值学习率。
warmup_num_steps:
预热阶段的总步数,前 1000 步为学习率上升阶段。 经验值:通常设置为总训练步数的 5%~10%,大批量训练或大模型场景需适当延长。
预热结束后可衔接余弦退火或线性衰减,形成完整的学习率调整曲,即预热 → 峰值 → 衰减。
常用的学习率衰减调整策略包括:
- 时间衰减:随训练时间逐步降低学习率,常见于传统机器学习模型,式-3
$$η_t =η_0 ⋅e^{−kt} 或η_t =\frac{η_0}{(1+kt)}$$
- 余弦退火(CosineAnnealingLR):周期性地将学习率从初始值\(η_{max}\)降至\(η_{min}\),适用于逃离鞍点并提升泛化能力,式-4
$$η_t=η_{min}+1/2(η_{max}−η_{min})(1+cos(π T_{cur}/T_{max}))$$
以下是包含衰减的学习率调度器配置,代码段9-4。
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 1000,
"total_num_steps":11000
}
},前面提到,在使用梯度累积的时候,需要同步调整学习率。梯度累积与学习率的调整本质上是等效批量大小(Effective Batch Size)与梯度更新步长的协同优化问题。梯度累积通过多次小批量梯度累加模拟大批量训练效果,而学习率需根据等效批量大小进行动态调整,以实现收敛速度与稳定性的平衡。
当累积步数为k、单步批量大小为b时,等效批量大小B = b×k。根据线性缩放规则(Linear Scaling Rule),学习率应调整为式-5
$$η_{new}=η_{base}×k$$
例如,当k=4时,学习率需放大4倍以匹配等效批量效果,调整后的学习率通常是预热阶段结束后的最终基准值,后续可能叠加衰减策略(如余弦退火),代码段9-5。
base_lr = 1e-4
accum_steps = 4
optimizer.lr = base_lr * accum_steps # → 4e-4Optimizer(优化器)
优化器(Optimizer)是机器学习和深度学习中的核心组件,用于调整模型参数,使模型在训练过程中逐步逼近最优解。它的核心任务是找到一组参数,使得模型的预测结果与真实数据之间的误差(损失函数)最小化。
大模型参数(如神经网络的权重)的初始值是随机设定的,优化器通过计算损失函数的梯度(即误差对参数的变化率),决定参数应该往哪个方向调整、调整多少幅度。
| 优化器 | 核心原理 | 适用场景 | 代表模型/框架 |
| SGD | 基本梯度下降,固定学习率更新参数 | 简单任务、理论验证 | 传统机器学习模型 |
| SGD with Momentum | 引入动量项,加速收敛并减少震荡 | 图像分类、RNN | ResNet、LSTM |
| Adagrad | 自适应学习率,对低频参数大幅更新 | 稀疏数据(如NLP) | Word2Vec |
| RMSprop | 指数加权平均历史梯度平方,缓解Adagrad学习率骤降问题 | 非平稳目标(如强化学习) | Deep Q-Network |
| Adam | 结合动量+自适应学习率,默认首选 | 大多数深度学习任务 | BERT、GPT |
| AdamW | 改进Adam,解耦权重衰减与参数更新 | 大模型微调 | ViT、LLaMA |
| LAMB | 针对大批量训练的Adam变体,引入信任区域 | 分布式训练(Batch>1万) | T5、Megatron-LM |
精度类型和混合精度(Precision Type)
LLM大模型中常见的三种精度类型:FP16(半精度浮点数)、BF16(Bfloat16)和FP32(单精度浮点数)。图片参考wiki
- FP16(半精度浮点数)
FP16,也称为Half-precision floating-point,在IEEE 754标准中定义为binary16,即使用16位二进制表示浮点数。它包含1位符号位、5位指数位和10位尾数位。由于其尾数精度实际上为11位(隐含了首位的1),FP16能够表示的动态范围相对较广,但精度较低。在深度学习领域,FP16常被用于加速训练过程,因为它可以减少内存占用和加快计算速度。然而,其较低的精度也可能导致梯度消失或爆炸等问题。

- BF16(Bfloat16)
BF16,或称为Brain Floating Point 16,是Google专为深度学习设计的16位浮点数格式。与FP16相比,其指数位增加到了8位,这使得BF16在保持相对较高的精度的同时,扩大了动态范围。在处理深度学习中常见的大数值范围变化时,BF16表现出良好的稳定性和效率,同时显著降低了内存和计算需求。

# 查看系统是否支持 bf16
>>> import transformers
>>> transformers.utils.import_utils.is_torch_bf16_gpu_available()- FP32(单精度浮点数)
FP32是使用32位二进制表示的浮点数,包括1位符号位、8位指数位和23位尾数位。相比FP16,FP32提供了更高的精度和更广的动态范围,因此在科学计算和深度学习模型训练中被广泛使用。特别是在需要大量精确计算的场景下,如模型微调、高精度推理等,FP32是保障结果准确性的重要选择。不过,它也需要更多的内存和计算资源。

混合精度训练是一种同时使用多种精度浮点数(如 单精度和半精度浮点数)进行模型训练的技术。通过混合使用不同精度的浮点数,可以在保证模型训练精度的同时,提高训练速度和减少显存占用,代码段9-7。
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2
},对于上述配置示例,有:
enabled: true
启用FP16混合精度训练模式,自动将部分算子(如矩阵乘法)切换为float16计算,同时保持关键操作(如Softmax、损失计算)为float32精度。
loss_scale: 0
动态梯度缩放模式(默认行为)。当设为非零值时表示固定缩放因子(不推荐),设为0时由系统自动调整缩放比例
loss_scale_window: 1000
梯度缩放因子更新的观察窗口大小。表示连续1000次迭代未检测到梯度溢出时,才增大缩放因子
initial_scale_power: 16
初始缩放因子为2^16=65536
hysteresis: 2
防止缩放因子频繁波动的缓冲阈值。需连续2次迭代无溢出才会增大缩放因子,而单次溢出即触发缩小。
使用示例,代码段9-8。
from torch.cuda.amp import autocast, GradScaler
model = YourModel().cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
scaler = GradScaler()
for data, target in dataloader:
optimizer.zero_grad()
with autocast():
output = model(data)
loss = loss_fn(output, target)
scaler.scale(loss).backward() # 放大损失值后进行反向传播
scaler.step(optimizer) # 应用放大后的梯度更新权重
scaler.update() # 更新缩放因子Weight Decay(权重衰减)
权重衰减(Weight Decay)是机器学习和深度学习中用于正则化模型的核心技术,旨在通过限制模型参数的复杂度来抑制过拟合。其核心原理是向损失函数中添加一个与权重相关的惩罚项,通过惩罚较大的权重值,迫使模型参数趋向于较小的数值,从而降低模型复杂度,减少对噪声数据的敏感度,提升泛化能力。
在模型训练阶段,权重衰减常与L2正则化等价使用。L2正则化通过在损失函数中添加权重的平方和作为惩罚项,间接实现权重衰减效果,这一方法在传统机器学习(如线性回归)和神经网络中广泛应用,式-6。
$$J_{regularized} (θ)=J(θ)+ \frac{λ}{2m} ∑_{i=1}^{n}θ_i^2$$
而在自适应优化器(如AdamW)中,权重衰减被改进为解耦实现(Decoupled Weight Decay),即权重更新时独立于梯度计算,更新公式为,式-7。
$$θ_{t+1}=θ_t−η(\frac{m^t}{(\sqrt{v ^ t} +ϵ)})−ηλθ_t$$
其中\(λ\)即为权重衰减系数。这种形式避免了传统Adam优化器中权重衰减与自适应学习率的耦合问题,显著提升了大模型(如Transformer)的训练效果。
这里简单解释一下,
在原始Adam优化器中,权重衰减通过L2正则化实现,即在损失函数中添加正则项 \(\frac{λ}{2}∥θ∥^2\) ,导致梯度计算时包含了正则化项:\(g_t =∇f(θ_t )+λθ_t\) 。这一设计引发两个核心问题:
- 自适应学习率的干扰:Adam的自适应学习率(基于二阶动量 \(v_t\))会缩放梯度,而正则化项 \(λθ_t\) 也被一同缩放,导致权重衰减的实际效果受学习率动态调整的影响。
- 参数衰减不均匀:不同参数的梯度大小差异会导致正则化项被不同程度缩放,某些参数可能衰减过度或不足,破坏模型泛化能力
而\(θ_{t+1}=θ_t−η(\frac{m^t}{(\sqrt{v ^ t} +ϵ)})−ηλθ_t\)中,
- 梯度\(g_t\)仅由原始损失函数计算,不含正则化项,避免自适应学习率对权重衰减的干扰。
- 衰减项 \(ηλθ_t\) 直接作用于参数更新,与梯度方向解耦,确保衰减强度仅由超参数 \(λ\) 和学习率 \(η\) 控制。
optimizer = torch.optim.AdamW(self.model.parameters(),lr=3e-5, weight_decay=0.1)Grad Clip(梯度裁剪)
在LLM训练中一种常见的现象是损失的突增,即损失函的数值在短时间内出现非预期的显著上升,通常伴随训练稳定性下降甚至模型发散。这种现象的本质是模型的参数更新方向或幅度失控,比如,反向传播时梯度值因链式法则累积而指数级增大,导致参数更新幅度远超合理范围。
为了解决这一问题,可以采取梯度裁剪(Gradient Clipping)的方法,把梯度限制在一个较小的区间内,当梯度的模长超过给定的阈值后,便按照这个阈值进行截断。
梯度裁剪通过修改梯度向量 g 的幅值,但不改变其方向(按范数裁剪)或直接限制元素范围(按值裁剪),使梯度满足: \( ∥g∥≤阈值\)从而保证参数更新步长 \(Δθ=−η\) 在合理范围内。在实际工程中,可以使用按范数裁剪或者按值裁剪。
- 范数裁剪
当梯度范数超过阈值时,按比例缩小梯度,保持方向不变。
"""
max_norm 是L2范数阈值,norm_type 可指定范数类型(如L1、L2
"""
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0, norm_type=2)- 按值裁剪
"""
直接限制每个梯度元素的绝对值
"""
torch.nn.utils.clip_grad_value_(model.parameters(), clip_value=0.5)需要注意的是,裁剪必须在反向传播(loss.backward())之后、参数更新(optimizer.step())之前执行,代码段9-9。
# 训练循环示例
for inputs, targets in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
# 梯度裁剪(在optimizer.step()之前调用)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()Dropout(神经元丢弃)
传统深度学习通常采用 Dropout 技术来避免模型过拟合,即在训练中随机将一些神经元的输出值置零来避免过拟合。
但是在大模型训练中,考虑到大规模的训练数据和模型中存在的归一化结构和正则化机制,同时模型训练通常采用混合精度(FP16/FP32),其数值表示范围有限,Dropout 引入的方差偏移会加剧低精度下的梯度溢出风险,需额外增加计算成本, 因此在大模型训练中Dropout 方法正逐渐淘汰掉。
对于成本增加,这里简单解释一下:
Dropout 的运行时成本在大模型中呈指数级放大。
- 显存占用:需生成与激活值同维度的随机掩码矩阵(Mask),对于千亿参数模型(如 GPT-4),单次前向传播的掩码存储消耗可达 40GB。
- 计算延迟:掩码生成和元素乘法操作使单步训练时间增加 8%-12%(NVIDIA A100 实测数据)
以上策略,需要相互配合使用,才能高效发挥作用。典型配置,代码段9-10。
{
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 1000,
"total_num_steps":11000
}
},
"fp16": {
"enabled": false,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2
},
"bf16": {
"enabled": false
},
"gradient_clipping": 1.0,
}还有其他优化策略,后文一一讲解。